С 2022 года в НИЯУ МИФИ в Лаборатории цифровой лингвистики Института фундаментальных проблем социо-гуманитарных наук разрабатывается лингвистическая интеллектуальная среда (ЛИС) «Рукописное наследие Древней Руси», которая будет способна распознавать церковно-славянские рукописи XI-XVIII веков и представлять их выборку под конкретный запрос. Проект поддержан в рамках Научного направления программы «Приоритет 2030».
Вход в Портал рукописного наследия Древней Руси
Для формирования корпуса изучаемых объектов специалисты лаборатории – сотрудники Института интеллектуальных кибернетических систем НИЯУ МИФИ и Института русского языка им. В.В. Виноградова РАН выбрали богослужебные книги – минеи. Таких книг в библиотеках, архивах и хранилищах музеев сохранилось больше всего, и что немаловажно, сохранилось в хорошем состоянии.

Каталог рукописей
«В целом, когда мы работаем с дефицитом достоверной информации, лучше иметь побольше источников, которые как можно полнее могут рассказать о языке, а служебные рукописные книги были в большом ходу, имелись в каждой церкви, да и печатать их начали первыми, – говорит руководитель проекта, доцент кафедры кибернетики НИЯУ МИФИ Дмитрий Демидов. – Сейчас у нас уже есть в цифровом виде примерно 250 книг (по 500 страниц каждая), хранящихся в РГБ, Историческом музее, областных библиотеках. Работа, которой мы занимаемся на первом этапе, если говорить на понятном для широкой публики языке, обратна тому, чем раньше занимались наборщики книг в типографии: они из букв составляли строки, а из строк – страницы, мы же обучаем машину распознавать границы текста, «вырезать» строки, буквы, выносные знаки, буквицы и вязь. Это называется сегментация, за ней идет классификация, чтобы потом к одному тексту можно было бы подобрать целый ряд подобных и на основании выборки, например, датировать рукопись, проследить как менялся текст, слово или знак на протяжении времени».

Доцент кафедры кибернетики НИЯУ МИФИ Дмитрий Демидов
Лингвистическая интеллектуальная среда задумана как человеко-машинный интерфейс с элементами самообучения. То есть в нее можно будет постоянно добавлять новые рукописи, которые искусственный интеллект будет распознавать и при этом постоянно подстраивать свои алгоритмы распознавания. Раньше ученым приходилось вручную набивать тексты рукописей. Бывало, что доходило до 150 вариантов одной буквы, ведь каждый писец вносил свои корректировки в текст – где-то это была сознательная редактура, а где-то просто ошибки, плюс особенности «почерка» конкретного человека. Сейчас результаты сегментации и классификации тысяч изображений доступны для проверки ученым в режиме онлайн. «Для машинного обучения важно, чтобы было достаточное количество образцов – тогда можно быть уверенным, что на «открытом поле», где ничего не размечено, нейронная сеть даст высокоточный результат. Если же материала будет недостаточно, то система сделает много ошибок. Каждая новая рукопись, которую мы обрабатываем, вносит свой вклад в донастройку моделей, «добавляет мозгов» программе и обучает весь программный комплекс. Чем больше мы обработаем рукописей на этом этапе, тем релевантнее будет ответ на запрос пользователя — будь то поиск по текстам или изображениям», – добавляет Дмитрий Демидов.
Церковно-славянские тексты имеют свои особенности, которых нет в других языках – это титлы, то есть надстрочные знаки сокращения слов, и выносные буквы. Пример сокращения слова с помощью титло известен всем –  , Иисус Христос, это сокращение можно найти на фресках и иконах в любой церкви. Были и другие: «б-ца» (Богородица), «мчн҃къ» (мученик). Сокращались также имена и звания царей. Но есть и более прозаические причины сокращения – допустим, слово не помещалось на строке, было принято выносить наверх определенные буквы, часто выносили «Д», «О», «М». Сокращения – это всегда несколько вариаций, одно и то же слово может быть представлено в совершенно разных видах, даже в одной рукописи, не говоря уже о разных рукописях. Словаря, который учитывал бы все виды слов и сокращений в церковно-славянском языке, не существует (поэтому параллельно в Лаборатории работают над созданием Морфологического словаря, где будут даны леммы со всеми словоформами и вариациями написания). Плюс – в рукописях масса нотированных страниц с «крюками» и «знаменами»: это безлинейное древнерусское нотное письмо с черточками, запятыми и точками, способ записывать движение голоса, ускорение или замедление темпа пения и звуковые акценты.
, Иисус Христос, это сокращение можно найти на фресках и иконах в любой церкви. Были и другие: «б-ца» (Богородица), «мчн҃къ» (мученик). Сокращались также имена и звания царей. Но есть и более прозаические причины сокращения – допустим, слово не помещалось на строке, было принято выносить наверх определенные буквы, часто выносили «Д», «О», «М». Сокращения – это всегда несколько вариаций, одно и то же слово может быть представлено в совершенно разных видах, даже в одной рукописи, не говоря уже о разных рукописях. Словаря, который учитывал бы все виды слов и сокращений в церковно-славянском языке, не существует (поэтому параллельно в Лаборатории работают над созданием Морфологического словаря, где будут даны леммы со всеми словоформами и вариациями написания). Плюс – в рукописях масса нотированных страниц с «крюками» и «знаменами»: это безлинейное древнерусское нотное письмо с черточками, запятыми и точками, способ записывать движение голоса, ускорение или замедление темпа пения и звуковые акценты.
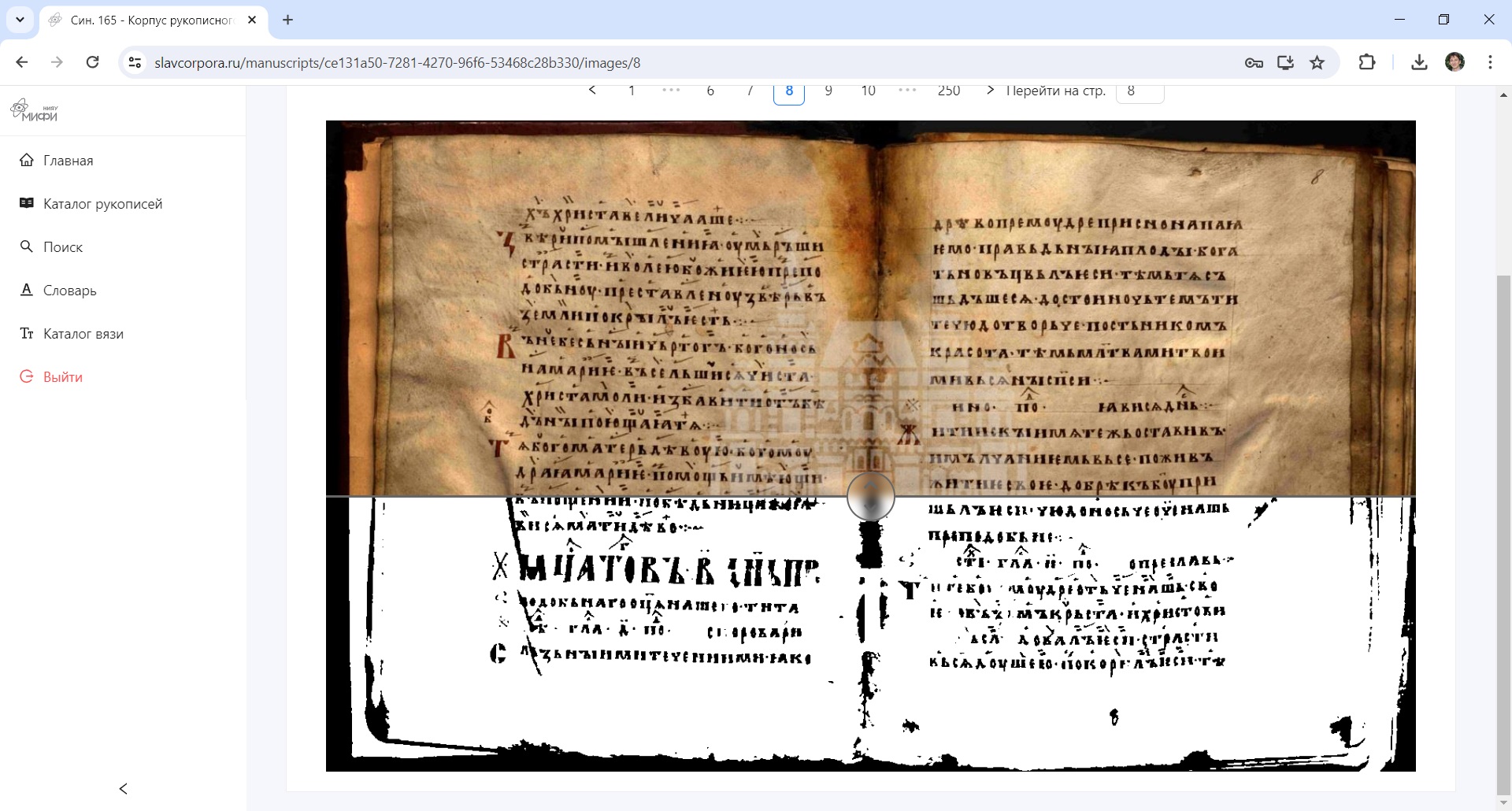
Постраничный просмотр в черно-белом режиме со «шторкой»
Как сам по себе церковно-славянский язык претерпел ряд изменений за 700 лет, так менялись и рукописные книги: появлялась пунктуация, развивались традиции украшения текста буквицами, орнаментами, вязью. Поэтому современные средства распознавания текста не годятся для таких рукописных материалов, необходимо разрабатывать новые алгоритмы и программное обеспечение, учитывающие эти тонкости: программа обработки текста должна уметь разделять текст на слова, не путать титлы с буквами, различать буквицы, уметь «читать» орнаменты и крюки, видеть филиграни (типографские водяные знаки на бумаге). Кстати, именно филигрань обычно дает самую точную датировку, поскольку произведённая бумага практически сразу пускалась в ход. Теперь прибавьте к этому, что не все страницы рукописей одинаково хорошо сохранились, где-то есть пятна, грязь, пожелтения, утраты, потрёпанность, поэтому разница в яркости изображения не всегда может служить достаточным основанием для его сегментации.
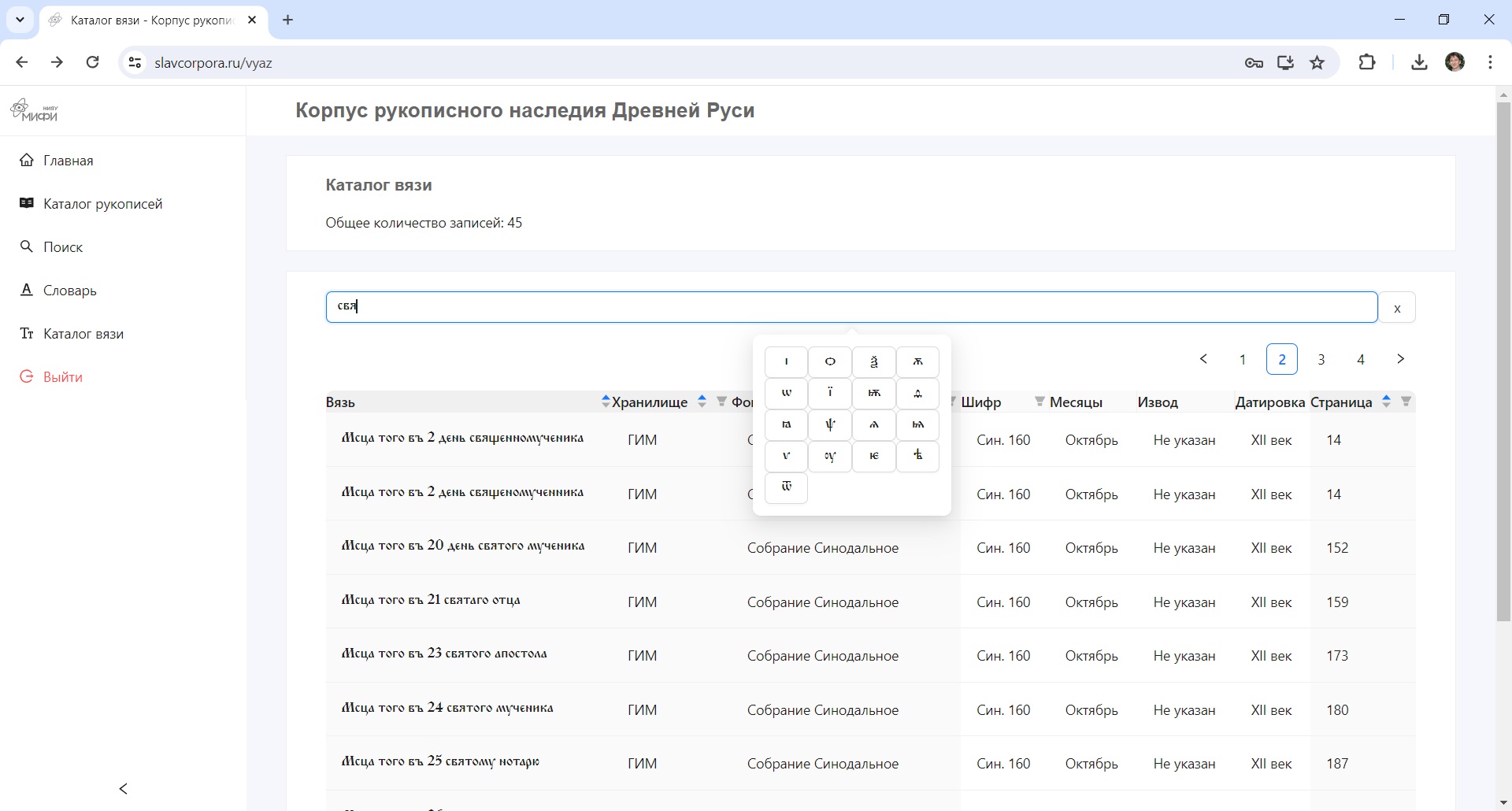
Пример поиска в каталоге вязи
Нейросеть должна научиться распознавать изображение в нескольких режимах сразу – в различных цветах, изгибах линии, примерно так, как это было в фильме «Хищник», когда с помощью пультика зрение переключалось в разные диапазоны. Для IT-специалистов это нетривиальная задача. В этом году команда разработчиков планирует классифицировать все 250 рукописей в первом приближении, это означает, что они должны быть полностью распознаны и сегментированы так, что можно было осуществлять приближенный поиск.
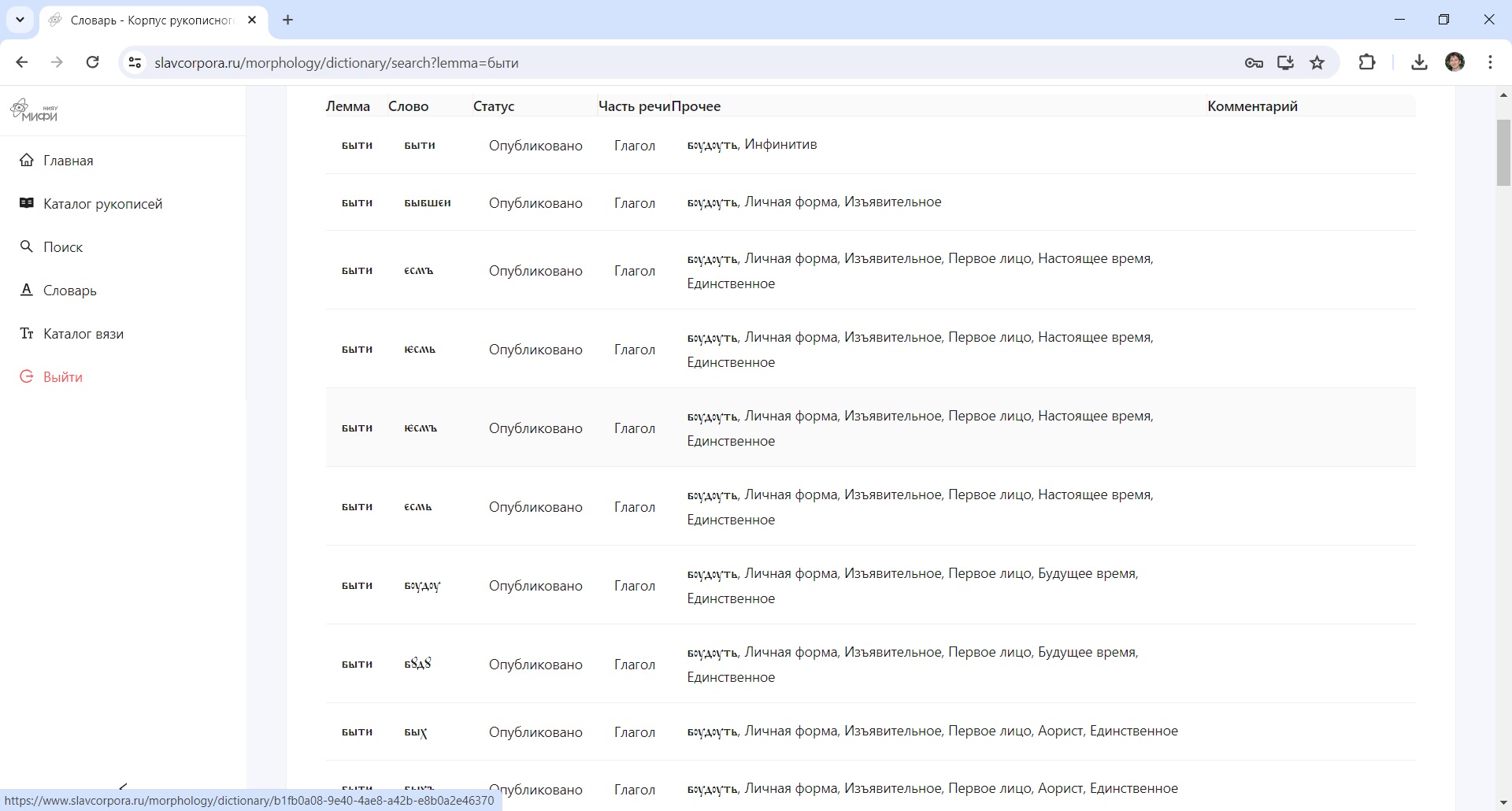
Морфологический словарь
У филологов же в этом проекте свои цели – создать инструменты для изучения средневековых текстов. «Почему историкам языка это интересно? Минеи – это огромный и практически не изученный корпус церковно-славянских текстов, содержащий службы на каждый день года, 12 томов, по одному тому на каждый месяц, – рассказывает ведущий научный сотрудник ИРЯ им. В.В. Виноградова РАН и МИФИ Александра Плетнева. – И нет инструмента освоения этого массива. Поэтому машинное обучение и нейросети, которыми занимаются в рамках этого проекта в НИЯУ МИФИ, даст филологам совершенно иные возможности. Они смогут работать сразу с огромными объемами похожих, но не идентичных текстов».

Ведущий научный сотрудник ИРЯ им. В.В. Виноградова РАН и НИЯУ МИФИ Александра Плетнева
Изучение и сравнение этих похожих, но всё же разных текстов даст исследователям возможность понять в исторической перспективе где, когда и почему происходили изменения в языке – в его лексике, синтаксисе, пунктуации, орфографии. Сейчас, например, можно увидеть, что в XV веке какое-то слово употребляли и писали вот так, а спустя два века – уже по-другому, но когда, где и почему оно изменилось, ученые не знают. А ведь история языка, кроме чисто лингвистического интереса, имеет отношение еще и к истории, этнографии, антропологии и т.д. Появляется возможность проследить связь происходящих в культуре процессов, например, какие рукописные школы существовали в тот или иной период, как они воздействовали друг на друга, чем это было обусловлено? Здесь ученые вступают уже в междисциплинарную область, которая открывает огромное поле для гуманитарных исследований.
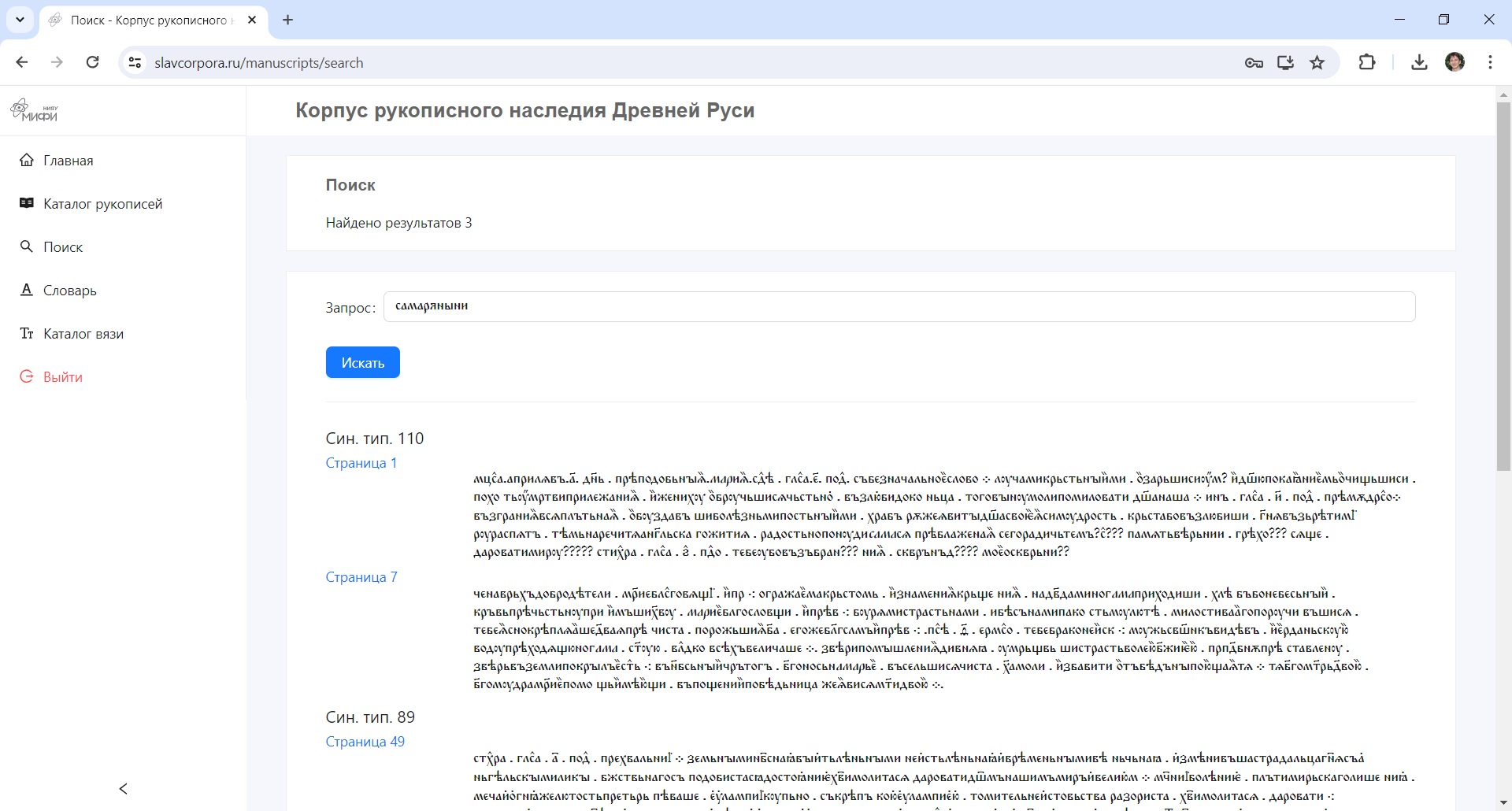
Пример полнотекстового поиска по каталогу рукописей
«Когда будут решены задачи распознавания и поиска, мы сможем в наших рукописях искать любые вещи, примерно так же, как это делается сейчас в Яндексе. Можно будет, например, сделать запрос в ЛИС по конкретному слову, словосочетанию, фрагменту вязи, буквице – как они менялись на протяжении 700 лет? И система выдаст все фрагменты, которые она найдет по интересующему нас вопросу, – продолжает Александра Плетнева. – В настоящее время у нас нет общедоступной системы распознавания славянских рукописей. Есть немецкая система Transkribus, но она, во-первых, платная, во-вторых, она требует специальной и довольно сложной настройки для каждого нового почерка, в то время как мы создаем самообучающуюся систему, способную распознавать рукописи разных эпох и разных почерков. И самое главное, Transkribus распознает отдельные рукописи, но не объединяет результаты распознавания в корпус, с которым могли бы работать исследователи. Наш же проект позволит увидеть развитие языка «в движении», увидеть все варианты использования интересующей вас буквы или слова – во всех рукописях, внесенных в базу данных. У каждого исследователя будет в системе свой отдельный кабинет, где он сможет решать те задачи, которые интересны именно ему. И что очень важно – это будет открытый проект, доступный всем. А дальше можно будет применить наработанные алгоритмы и для рукописей на других древних языках, причем не только славянских – зарубежные исследователи уже проявляют большой интерес к этому проекту».
О достижениях наших ученых недавно сообщили «Известия».